

Design an LLM-based question-answering chatbot on enterprise/private data.
The application should take the question as input and generate the answer based on the knowledge provided in the document and personalize the answer per the user question.
The model should be able to prevent hallucinations.
Approach
This approach process of 2 steps:
Data Ingestion
LLM Based Answer Retrieval
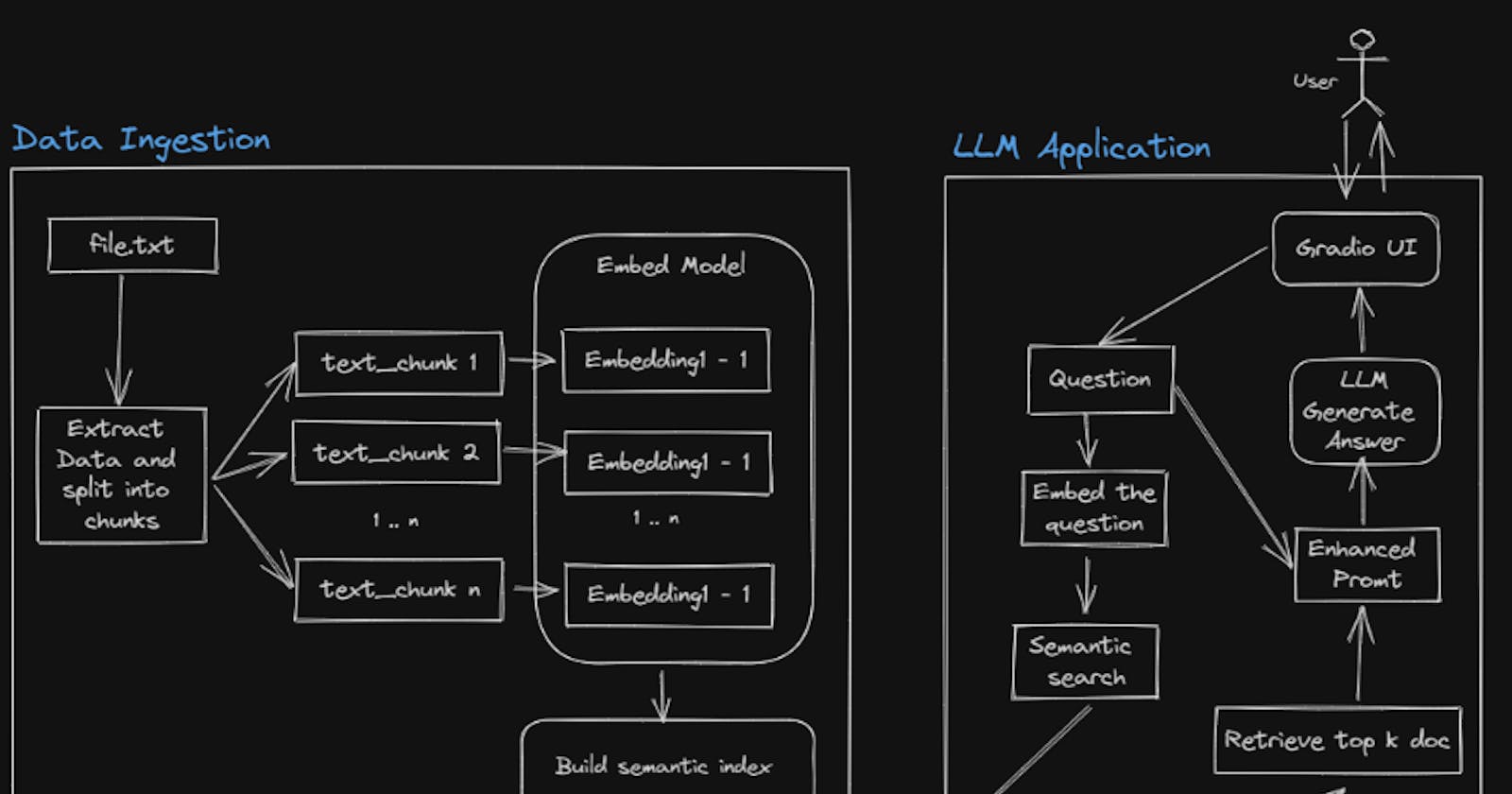
Data Ingestion Steps -
Load and extract the Txt file
Split the extracted data into smaller chunks
Embed the text chipmunks using any embedding model e.g.; hugging face instruct embeddings
Build and semantic index of each chunk
Ingest the index into a vector database as a knowledge base
LLM-Based Answer Retrieval steps -
Take the input from the user with a UI (Gradio)
Embed the question using the same embedding model which is used for data ingestion
Semantically search and retrieve the relevant text chunks using a knowledge base (vector database)
Enhance the prompt using both questions and retrieved doc
Call the LLM model with an enhanced prompt and generate the answer
Display the answer to the user using UI (Gradio)
Assumptions
No OpenAI LLM API call. Only using open source pre trained LLM.
The model should run on CPU (because of computing constrain)
Solution
Library used -
LangChain - For LLM orchestration
Milvus Vector Database for embedding storage
InstructorEmbeddings - For vector embedding of docs
llamacpp - LLM model
Gradio - Web interface
W&B - For prompt/experiment tracking
Application Flow Diagram

Performance Evaluation
Using weights and bias to keep track for all the prompts results and manually checking the output’s performance.
Using BertScore as a performance metric.
Drawbacks of the current model
The performance of the current model is not very great and the reason could be that this model is a quantized model designed to run only on CPU, therefore, less number learned parameters and also the context window of this model is not large enough to pass all the relevant docs at once.
Future Scope
Use SOTA open-source model with a larger context window (like Falcon)
Finetune the model with instructions
Create one more layer of LLM to validate semantic search retrieval of docs.
Experiment with different prompt templates
Experiment with guardrails for edge cases
Experiment with the chunk size of the doc and k number of retrieved documents for the prompt.
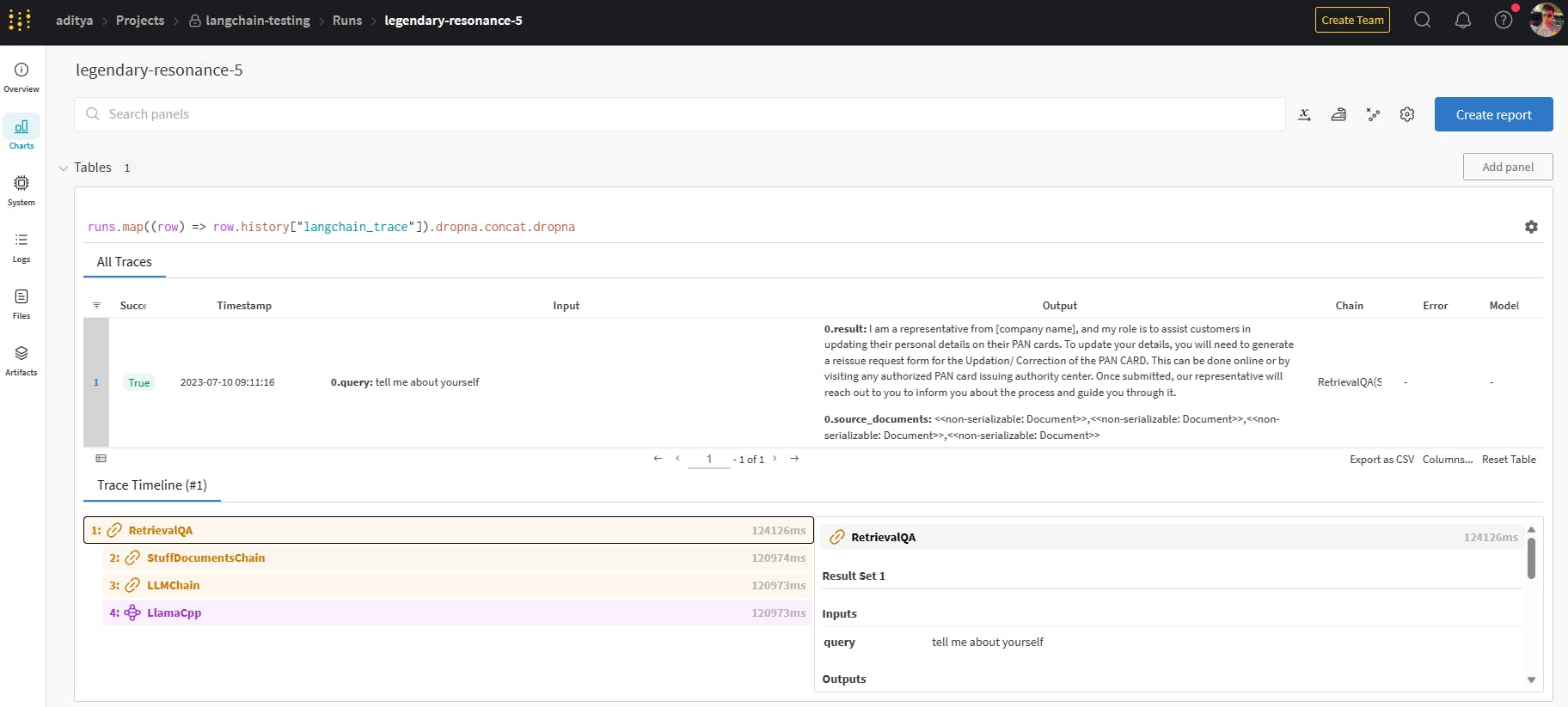
Output Screenshots
User Interface for prompting -
W&B experiment log -